Architecture — the three stacks
Each module is trained or derived separately and run together. The learning-mechanism split is deliberate: perception is learned & dynamic, control is gradient-free, exploration is heuristic.
Stack 1 — Compass deterministic heuristic
The frontier driver (_choose_target): scores reachable cells by uncertainty / unexplored-ness, discounted by BFS distance, with anti-overlap (avoid neighbor-claimed cells) and a soft connectivity bias lam_frontier. No learning. Two findings reshaped it:
- The compass is the dominant link-breaker: 97–100% of comm-link breaks come from frontier agents following the compass out of range (relays cause ~0–3%), and the soft knob
lam_frontieris inert (coverage/connectivity unchanged across λ = 0→6). - Fix: a hard connectivity guardrail — mask any compass step that severs an agent's last link, fall back to the best connectivity-preserving cell. Refinement from the resilience literature: target algebraic connectivity λ₂ computed from the belief (not a localization oracle) as a constraint; for the adversarial setting target graph robustness r (W-MSR), since λ₂-connected ≠ r-robust.
Stack 2 — Role-switcher Evolution Strategies
A small policy over 7 graph-criticality features → P(relay), wrapped in a hysteresis switcher (enter relay if P>hi or degree = 0; release if P<lo and degree recovers). Frontier → compass; relay → hold / rejoin. Trained by ES, not actor-critic: AC's shared team advantage made roles structure-blind, whereas ES sidesteps credit assignment and lets structure-awareness emerge from feature-conditioning + whole-team fitness.
Mission-safety degree-budget. An agent that has lost more than K neighbors (degree < N−1−K) is a "safety break." It is tracked, fed to the switcher as a feature, and penalized in the ES fitness — the bridge that lets ES learn selective relaying. Refinement: pose connectivity as a constraint (maximize coverage subject to a floor), not a weighted reward term — the weighted sum is what produced the clump and freeze failures.
Coordination upgrade (no consensus). Agents broadcast role-intent + a relay-fitness (criticality) score and best-respond to neighbors' last-step intents; criticality rank breaks symmetry, so two agents never redundantly hold the same link or simultaneously abandon it.
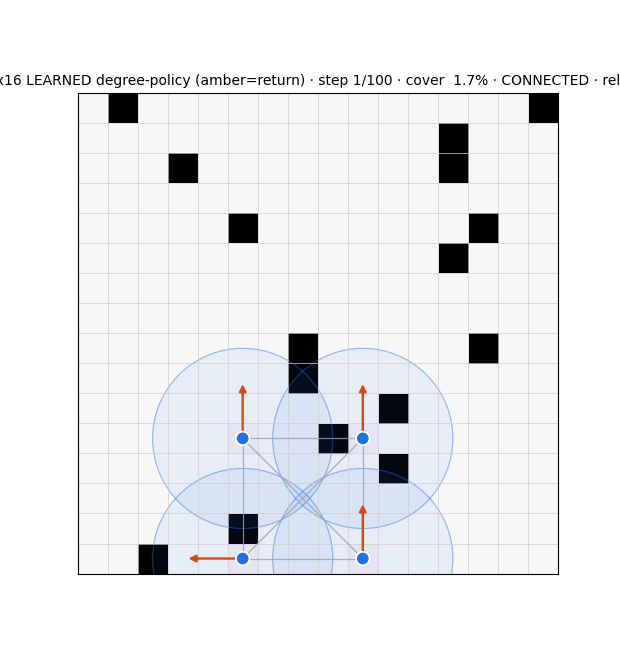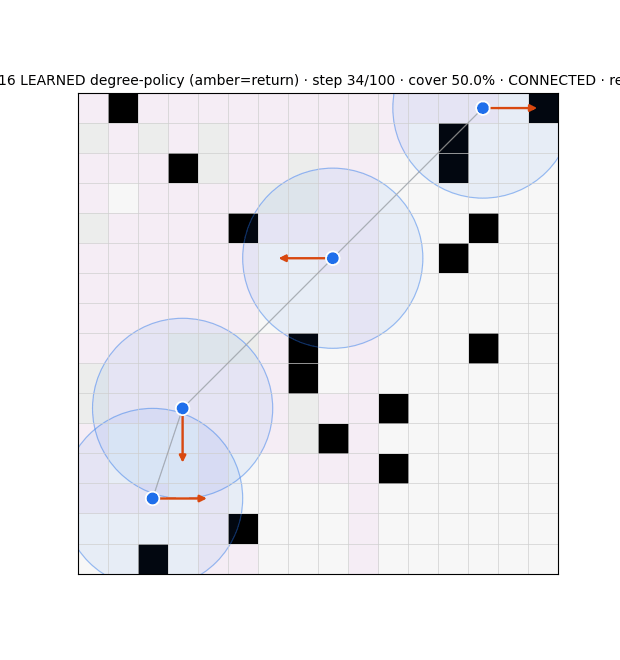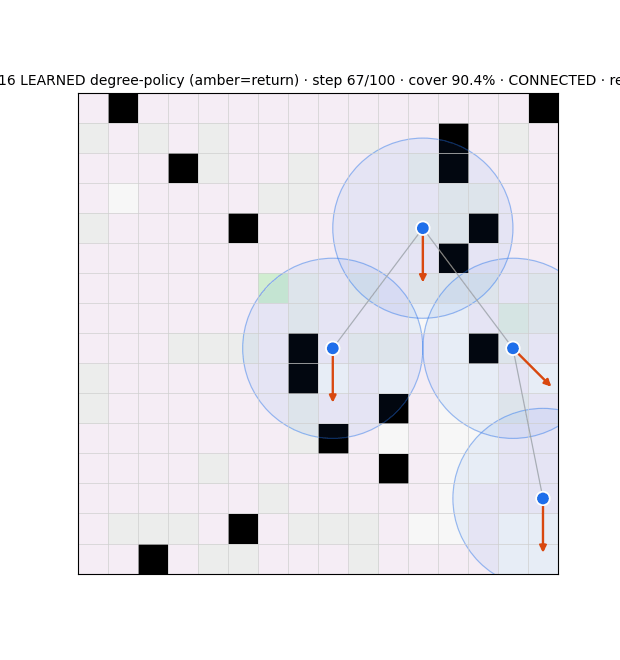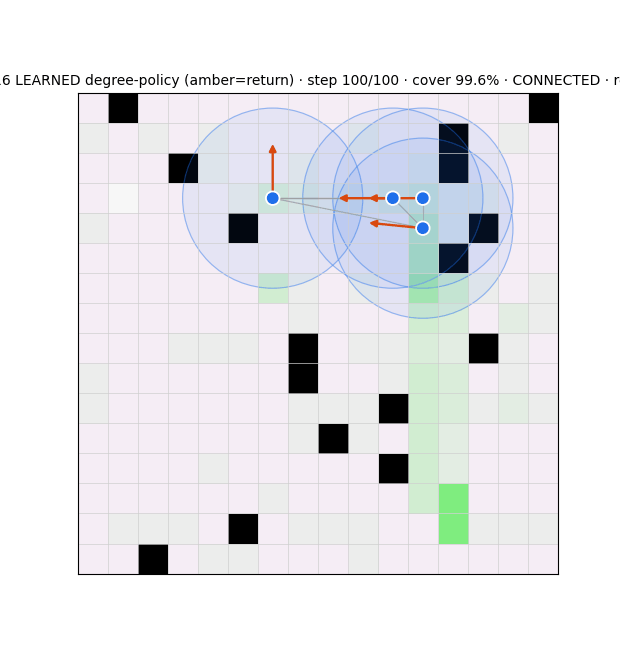
Stack 3 — Graph belief recurrent GNN, learned
Each agent runs a recurrent message-passing belief (graph-convolutional recurrent network: a GNN over the comm graph + a per-node GRU state + a bilinear adjacency decoder) to estimate the whole communication graph from partial, gossiped information.
- Size-invariant by design: shared weights, mean aggregation, comm-range-relative offsets, capped raw degree (not deg/(N−1)) — so one trained belief runs at 16×16/4 and 32×32/10 alike.
- Trained by privileged distillation (the true graph as the per-step target) via backprop-through-time — not snapshot-supervised, because real estimation is integrating neighbor information over time, which a feedforward net cannot represent.
- Dual-use: the belief is the agents' model of "what the graph should look like" — hence simultaneously the covert attacker's target and the team's stealth detector (behavior diverging from the belief's prediction is anomalous even within global bounds).
What's actually wired — the as-built audit 2026-06-22
The sections above describe the intended design. An audit requested to inventory every machinery, both learning and heuristic found the running system is different: it is not one interlocked three-stack design but two separate controllers plus an unplugged belief. The three stacks do not yet interlock — what is actually learned is thin, and the belief sits outside both control loops.
| Stack | What runs | What is learned |
|---|---|---|
Stack A — ES / relay controllerswarm_explore/relay_mission.py |
~95% heuristic. Hand-coded: the compass _choose_target (where to go), herd_target, A*/BFS pathing, gossip merge, comm-graph build (build_adjacency / compute_components), collision rules, and the hard connectivity backstop. |
Only a 145-parameter role gate (7 hand-crafted graph-criticality features → 16 → 1 = relay probability), trained by OpenAI-ES. Stack A never learns where to go. |
Stack B — MARL / PPO controllerexamples/lib/_marl_core.py + marl_attn.py |
The whole policy is learned: CNN perception + attention coordination (AgentAttnAC full self-attention, or GraphAttnAC masked over comm-graph neighbors). Hand-shaped reward. |
Emits direct 1-step move logits (5-way). No A*, no belief module, no goal abstraction. The myopic 1-step move head is the "action-representation bottleneck." |
The GCRN graph belief is trained but unplugged. The recurrent message-passing belief trains well and transfers zero-shot (95.6% @16 → 72.5% @32), but it is wired into neither Stack A nor Stack B. It exists as a module, not in any control loop.
Where is the Fiedler value estimator? It is an exact eigendecomposition oracle, not a distributed estimator. In make_fiedler_policy: L = diag(adj.sum) − adj, then eigenvalues, eigenvectors = numpy.linalg.eigh(L), with λ₂ = ev[1]/n and each agent's own Fiedler component evec[:,1] fed in as 2 extra features (a 9-feature gate, 177 params). It is not the distributed Yang–Freeman–Lynch λ₂ estimator from the MRS canon; it needs the global graph, so it is not deployable under partial information; and empirically it did not help — the perfect Fiedler oracle produced 0–2% relays and connectivity worse than baseline at scale (16% vs 32% @32×32, 14% vs 22% @40×40).