Article · working draft
Covert micro-to-macro misbehaviour and mission resilience in cooperative exploration swarms
Zymera / RedWithinBlue research program · active work in progress, 2026
Introduction
Swarms of autonomous agents that must cover or monitor an unknown environment cannot rely on a central coordinator: they sense locally, act locally, and stitch a shared picture together over a range-limited communication graph. That shared picture — the team's belief — is what makes cooperation possible. It is also a vulnerability. A single member that has been compromised does not need to attack anyone physically; it can simply mislead, or fail to contribute to, the belief the rest of the team depends on. The damage is emergent: a small, local, hard-to-detect deviation aggregates, through the interaction graph, into a macro-level mission failure.
This micro-to-macro pathway, under covert deviation, is the question we study. It sits in a gap between three mature literatures that do not currently meet1,2: connectivity-aware control and role allocation (which assume benign, often homogeneous teams), covert poisoning of cooperative reinforcement learning (which lives on abstract game benchmarks, not spatial missions), and resilient consensus theory (whose r-robustness guarantees assume adversaries are detectable outliers — precisely what a stealthy agent evades). We make the question precise with a formalism, instantiate it in an open testbed, and report what covert misbehaviour actually does.
Results
A decentralized connectivity-aware coverage engine
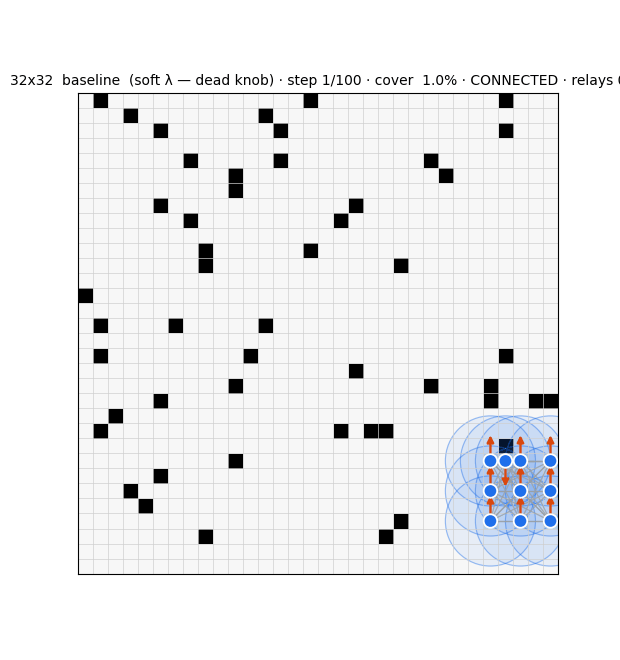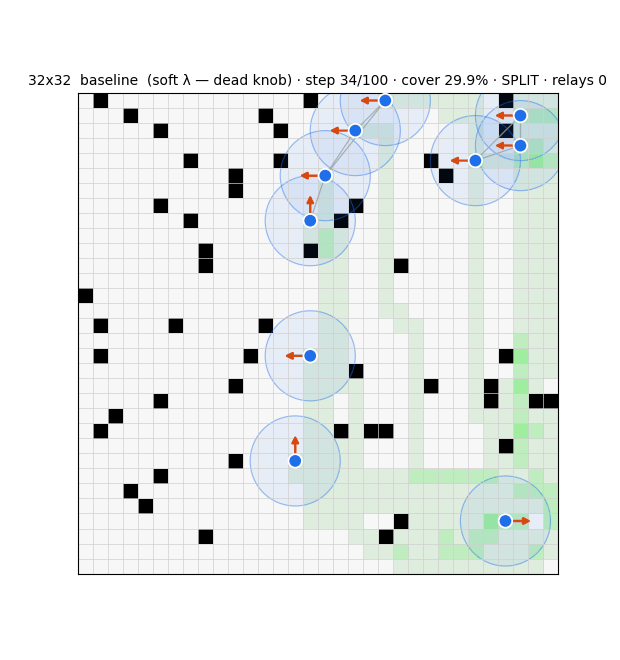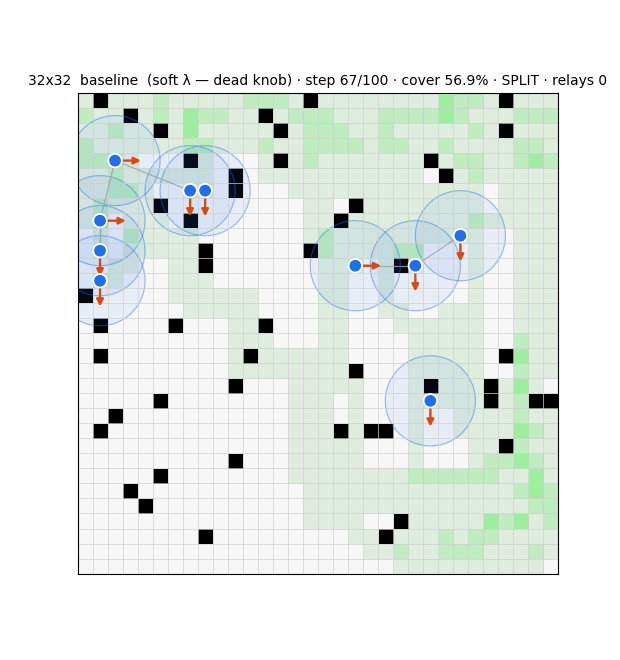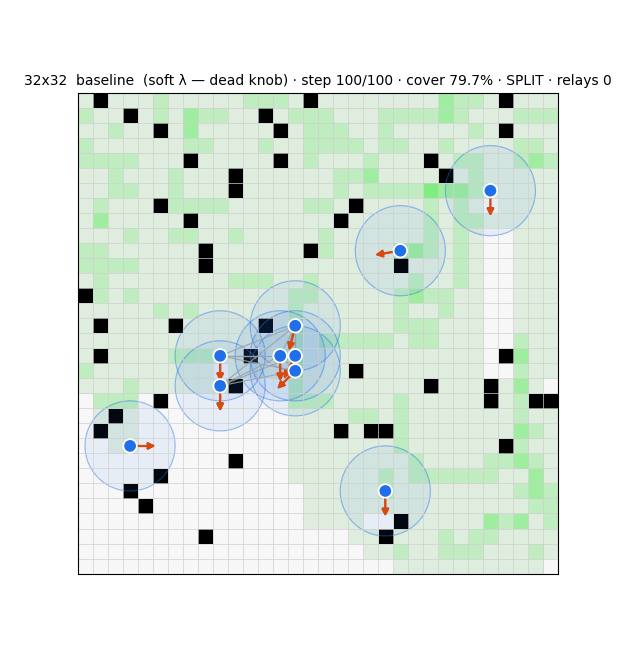
The substrate is a swarm that drives every cell of a grid to "covered" while keeping its communication graph connected over a fixed range. Each agent runs three modules (Fig. 1): a deterministic compass that steers toward uncertain frontier cells; an evolution-strategies role-switcher that decides, from graph-criticality features, whether to act as a network-holding relay or an exploring frontier agent; and a learned graph belief that estimates the whole communication graph from partial, gossiped information. Coverage is essentially solved — a learned frontier-attention policy reaches 97.7% and generalises across grid sizes — but a pure coverage optimiser disperses the swarm, collapsing connectivity to 32%3. Resolving that tension is the work.
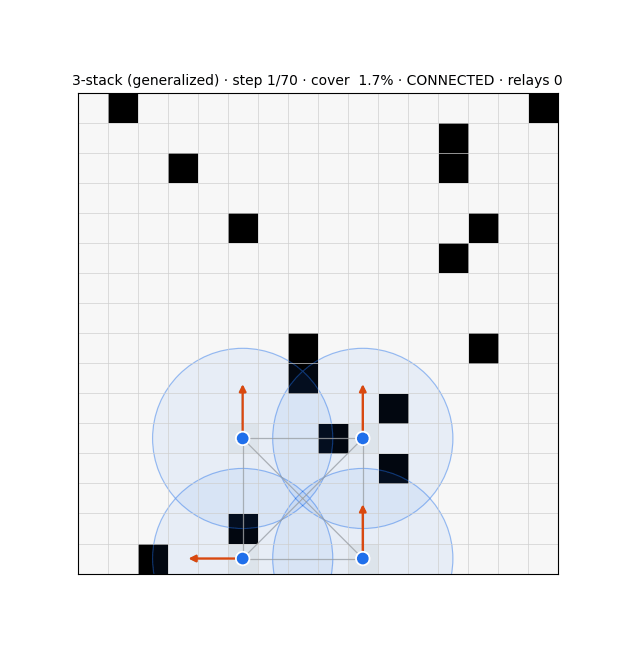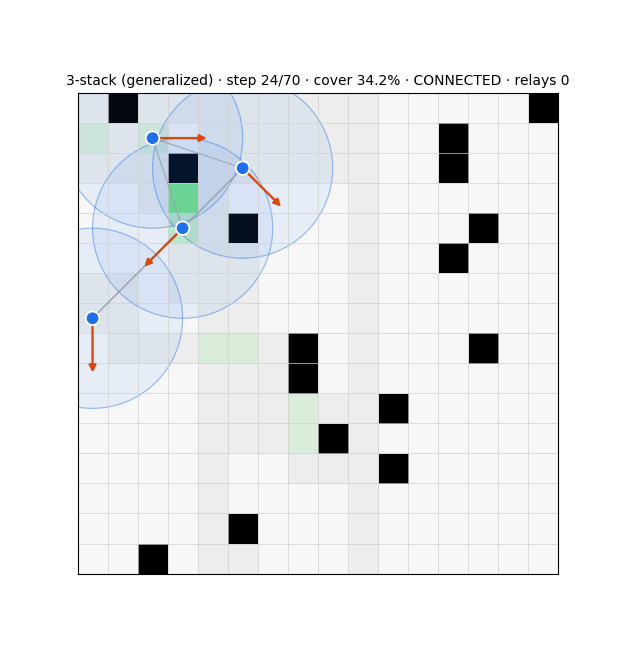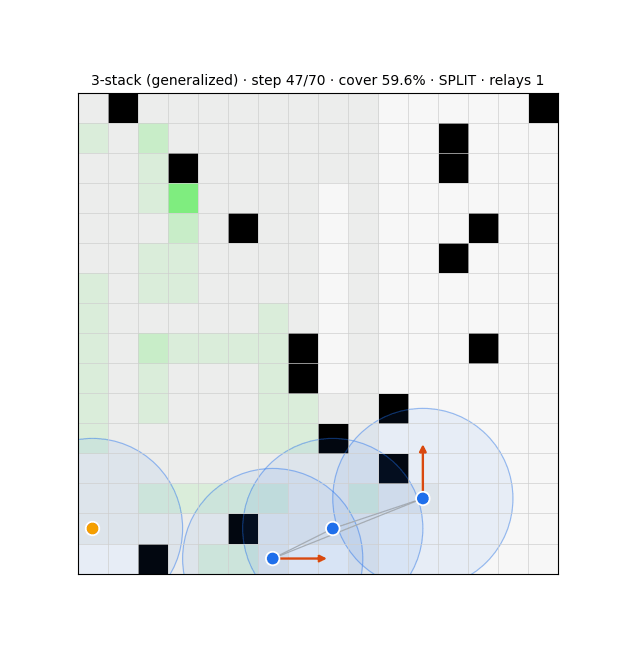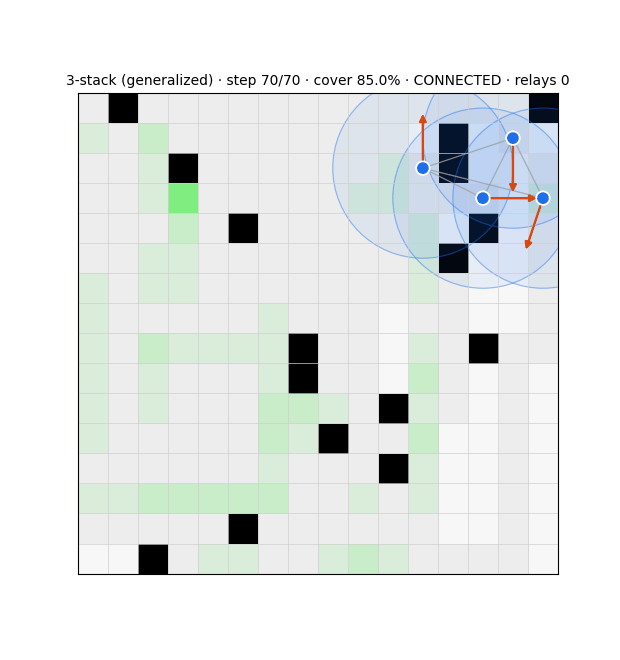
Two control principles recur. Connectivity is best enforced locally and as a hard constraint: masking any move that would sever an agent's last communication link guarantees integrity and beats a soft connectivity penalty by ~20 points of coverage, whereas a global algebraic-connectivity leash, which agents cannot compute from local information, underperforms a local degree floor. And reward must use a threshold, not a maximiser: a connectivity bonus is maximised by a useless huddle, so capping the rewarded component size removes the clump incentive.
A size-invariant graph belief that transfers across scale
Estimating the global graph from local gossip is a dynamic, distributed inference problem, not a one-shot classification. A feed-forward snapshot estimator reaches 88% adjacency accuracy at the training scale but collapses to chance out of distribution. Re-casting it as a recurrent message-passing network — a per-node gated recurrent unit over the communication graph with a bilinear decoder, trained by privileged distillation against the true graph — and constraining it to be size-invariant (shared weights, mean aggregation, communication-range-relative features) makes a single trained belief portable. It reaches 95.9% at 16×16 with four agents and, with no retraining, 72.5 ± 1.2% at 32×32 with ten agents (chance 45.9%); a single fine-tuning map at the new scale lifts it to 80%, within ~1 point of the full-data ceiling.
Connectivity at scale is geometrically bounded
Driving the role-switcher with the belief at the larger scale repeatedly failed, in instructive ways: the optimiser collapses either to an all-relay huddle, to a flat-fitness freeze, or to suppressing relaying altogether, and a zero-shot local switcher (60% coverage / 36% connectivity) remained the best operating point. The reason is not the policy. At ten agents, communication-range five, on a 32-wide world, the swarm must fragment to cover the area; holding the local bridges an agent can see cannot rejoin components that have drifted apart, and the exploration compass — with no connectivity awareness — is responsible for 97% of all link breaks (Fig. 2). Global single-component connectivity is bounded by geometry, not by the controller. This negative result reframed the project: the failure modes are themselves benign micro-to-macro amplifications, a preview of what a deliberate covert agent would exploit.
What covert misbehaviour actually does
We instantiate the adversary as a centralised controller of k of n agents in a two-player zero-sum partially-observed game, and run a compromise sweep on a 16×16, five-agent fixture4. A single compromised agent already pushes the team below the 90% coverage threshold (the misbehaviour-budget knee is at one agent); two inflate variance more than the mean. The mechanism is the surprising part:
- Withholding, not corrupting. Actively injecting a false belief is worth ≤1 point of damage; the real cost is the team excluding a flagged member's scans and re-covering ground — a delay channel, not a destruction channel.
- Damage scales with k, not the attack rate ρ. Mission damage is ~10× more sensitive to the number of compromised agents (+5.3 points each) than to per-step attack rate, whose effect is flat-to-defender-favourable. Two closed-form damage models — additive and concentration — were both falsified on a held-out cell (z > 4).
- The quietest attacker is the most damaging. A do-nothing "stay" adversary (+14.8 points) beats a trained one (+13.6), because a co-evolved defender routes around the trained adversary's predictable behaviour.
- Co-evolution is a defender-side fragility. A naïve defender out-defends a co-evolved one against the same adversary by ~7 points (z = 7.18) — the co-evolved defender overfits its training adversary.
- The connectivity guardrail is dual-use. Damage is non-monotone in the disconnect-grace budget, with an attacker-optimal sweet spot; removing the hard guardrail entirely can help the defender, because the constraint had also been limiting the defender's own motion.
Discussion
The covert regime is exactly where the standard defences fall silent. Resilient-consensus theory tolerates adversaries by discarding the most extreme neighbour values; a stealthy agent, by construction, stays within nominal bounds and is never an outlier. Our results suggest the productive defender response is not outlier rejection but model-based anomaly detection on the shared belief itself: an agent whose behaviour diverges from what the team's belief predicts is suspect even when it looks locally normal. The same belief is thus dual-use — the attacker's surface and the detector — and the natural object of study is a stealth–damage frontier: the maximum macro damage achievable per unit of detectability budget, with resilience defined as pushing that frontier down.
Two cautions generalise beyond this domain. Co-evolutionary training, the obvious way to "harden" a defender, produced a defender that was more fragile to an off-distribution adversary than a naïve one — a concrete instance of robustness-overfitting in adversarial co-training. And the strongest covert move was inaction, which no rate-based detector flags. Honest limitations: connectivity claims at scale are zero-shot/few-shot transfer under a CPU-only budget; the literature positioning rests partly on direct reading after a tooling failure; and the relay-role's novelty is defensible only as a conjunction (spatial mission + role/position + learned belief + stealth-frontier), not as any single ingredient.
Methods
Formalism
The mission, not the agent, is the unit of analysis. A team of n agents acts under a Dec-POMDP with shared reward, augmented by a time-varying interaction graph G(t) whose edges carry messages; each agent i chooses ati from its local history. Mission state carries a health indicator Φ(s,t) ∈ [0,1] and a viability kernel (states admitting ≥(1−δ) safe completion); success, degradation, and failure are trajectory-level properties. A threat is a deviation profile: a compromised set C of size k, an activation pattern, a replacement policy, an amplitude budget (a total-variation bound on the deviation), a stealth budget (a KL bound for local undetectability — the formal meaning of "covert"), and an intervention/break budget. Propagation is captured by a one-step influence (the total-variation shift a deviation induces on a neighbour's input). Resilience is reported through four metrics parameterised by threat intensity: robustness (worst-case performance ratio), brittleness (sharpness of collapse at the frontier), elasticity (graceful-degradation rate), and recovery (post-degradation value and time). A worked instantiation — phantom-coverage injection on a shared-exploration mission — shows a local lie propagating through frontier sharing into mission-level coverage loss.
Architecture & learning
Compass (deterministic): score = uncertainty − crowding, distance-discounted, with anti-overlap and a soft connectivity bias. Role-switcher: a small multilayer perceptron over seven graph-criticality features (degree, budget-overspend, detachment, 2-hop cut-vertex, component fraction, local-unexplored density, coverage progress) producing P(relay), wrapped in a hysteresis switcher and trained by OpenAI-ES with a mission-safety fitness (coverage + connectivity − degree-budget violations); a stochastic-relay objective is used during training to keep the fitness landscape non-flat. Actor-critic was tried and discarded — its shared team advantage yields structure-blind roles. Graph belief: a graph-convolutional recurrent network (per-node GRU + mean-aggregated message passing + bilinear adjacency decoder), size-invariant by shared weights, mean aggregation, communication-range-relative offsets and capped raw degree; trained by privileged distillation (true adjacency as a per-step target) via backprop-through-time with weight decay, gradient clipping, early stopping and five-fold cross-validation.
Evaluation
Policies are evaluated by sampling π at ε = 0, never by argmax: argmax destroys the spawn-time symmetry-breaking the policy relies on and inflates catastrophic-failure rate from 0% to ~46%. The adversarial study uses a centralised red controller trained by coevolutionary evolution strategies (population 8, 20 generations), with a pre-registered learning-detection rubric (Mann–Whitney + early-vs-late trend + non-degenerate action distribution) and negative controls. Code: github.com/bijanmehr/Zymera_env.
References
- Systematic review, connectivity-aware role allocation: two non-overlapping camps (connectivity-but-homogeneous vs. roles-but-connectivity-blind). See Gap.
- Covert poisoning of cooperative MARL is an active subfield on game benchmarks: One4All (2022), BLAST (2025), and related backdoor attacks; resilient-consensus / r-robustness (W-MSR) assumes detectable adversaries. See Gap.
- Frontier-attention coverage policy: 97.7% coverage, size-agnostic, connectivity 32%. See Findings and Journey.
- Stealth Attacks on Swarms — two-player zero-sum POSG, the compromise sweep and adversarial-model validation (RedWithinBlue). See Findings and Docs.
Threat model
The adversarial study (Stealth Attacks on Swarms: Adversary Modeling from a Zero-Sum Game Perspective) frames the problem as a two-player zero-sum partially-observable stochastic game on the cooperative Dec-POMDP / POSG tuple G = ⟨I, S, {Ai}, {Oi}, P, O, R, γ, ρ0⟩. Team blue (the n nominal agents) is decentralised: each agent i picks ai,t ∼ πi(τi,t, m̄i,t) from only its own local history and the messages it receives — there is no central controller with the joint state or observation. Team red is centralised: it coordinates interventions across its compromised agents and over time toward a single objective (mission degradation), even without knowing the full state or the communication graph. The game is imbalanced — blue holds all n agents, red influences at most k < n — and zero-sum: Jred(π, φ) = −J(π, φ). The communication channel itself is not tampered with; honest agents receive whatever is broadcast, but compromised agents may emit plausible messages and actions that steer the swarm toward poor outcomes.
The four stealth budgets
A team-red strategy φ ∈ Φk selects an unknown compromised set C ⊆ I and replaces the behaviour of those agents, subject to four explicit budgets:
| Budget | Symbol | What it bounds |
|---|---|---|
| Compromise size | k | How many agents red controls: |C| ≤ k < n. |
| Per-step distortion | ε | How noticeable each deviation is: d(π̃i, πi) ≤ ε per step (a norm/KL/detector-score bound — the formal meaning of "covert"). |
| Intervention window / cadence | Tint | How often red is allowed to act: Σt 𝟙[π̃i ≠ πi] ≤ Tint. |
| Attack aggressiveness / rate | α | Allowable detectability level, e.g. ℙ(detected | φ) ≤ α, trading damage against exposure. |
Blue solves π⋆ ∈ arg maxπ minφ∈Φk J(π, φ) (worst-case-robust mission return); red solves the complement. The footprint quantity of interest is the mission damage ΔJ(k) = J(π; clean) − minφ∈Φk J(π, φ), and especially k⋆(θ) = min{ k : ΔJ(k) ≥ θ } — the smallest number of compromised agents at which mission failure crosses a degradation threshold θ. (In the 16×16 / five-agent fixture this knee sits at a single agent.)
Research questions
- Minimum red-team footprint. What is the smallest compromise size k⋆(θ) needed to force ΔJ(k) ≥ θ, and how does it scale with swarm size n and communication connectivity?
- Stealthy worst-case attacks. Under distortion budget ε, intervention budget Tint, and detectability level α, what is the achievable trade-off between mission degradation and stealth — the Pareto frontier between ΔJ and detection probability / delay?
- Which attack surfaces dominate. When red can influence at most k agents, which intervention channel — messages vs. observations vs. actions — yields the largest worst-case degradation under the same budgets, and how does this depend on the attacker's knowledge of policies or the communication graph?